GPT-5.5 Launch
OpenAI has just unveiled GPT-5.5, its most powerful and versatile flagship model to date. This model represents a new level of intelligence, evolving into the native brain of the Agent era.
The highly anticipated “Spud” has finally arrived.


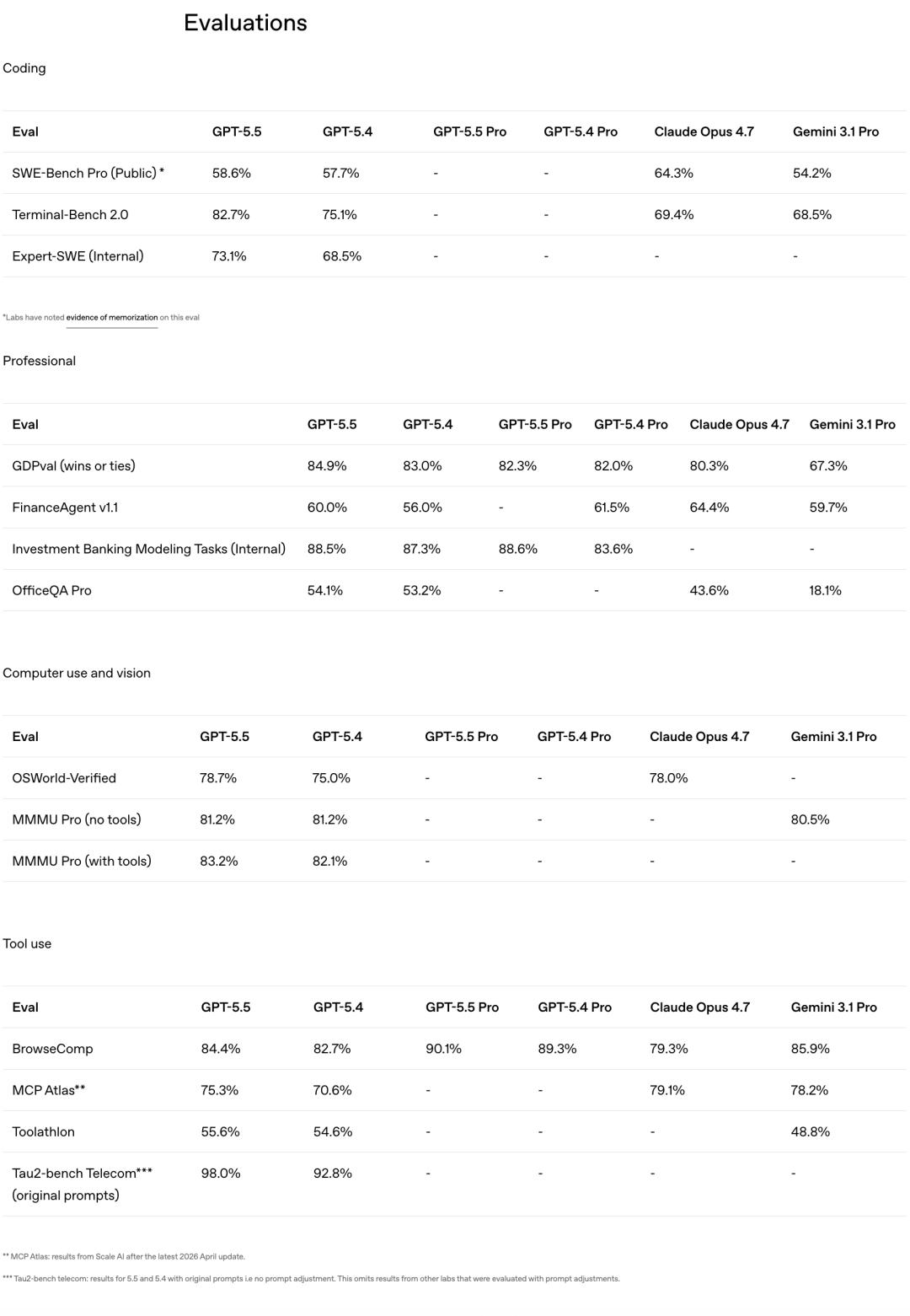
Notably, GPT-5.5 has achieved top scores across all benchmark tests! In programming, reasoning, mathematics, and agent tasks, it has outperformed Claude Opus 4.7 and Gemini 3.1 Pro.
Compared to its predecessor, GPT-5.5 represents a significant leap, showcasing a clear generational gap.
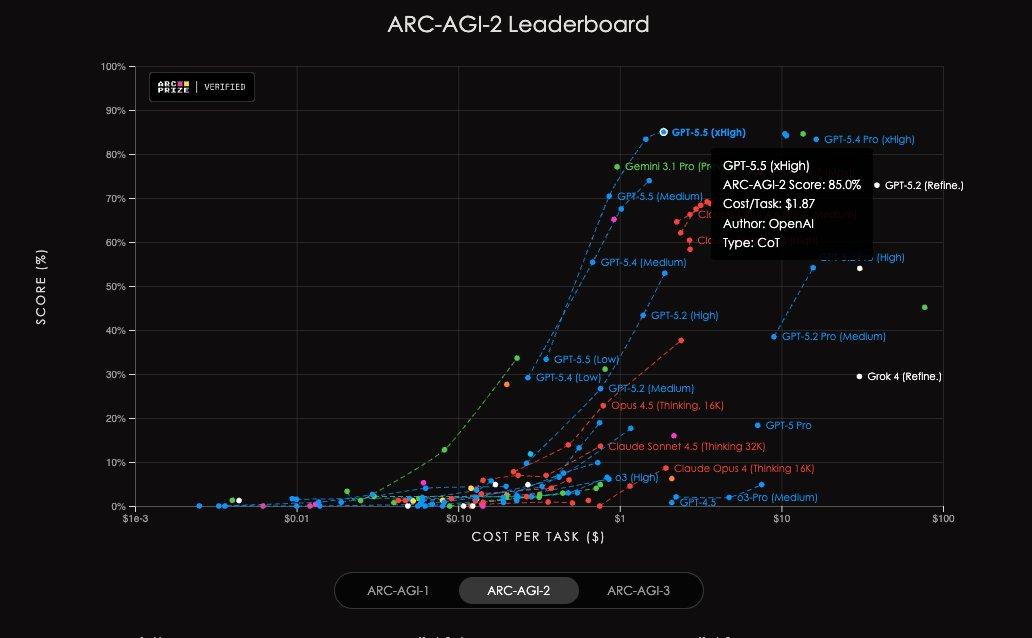
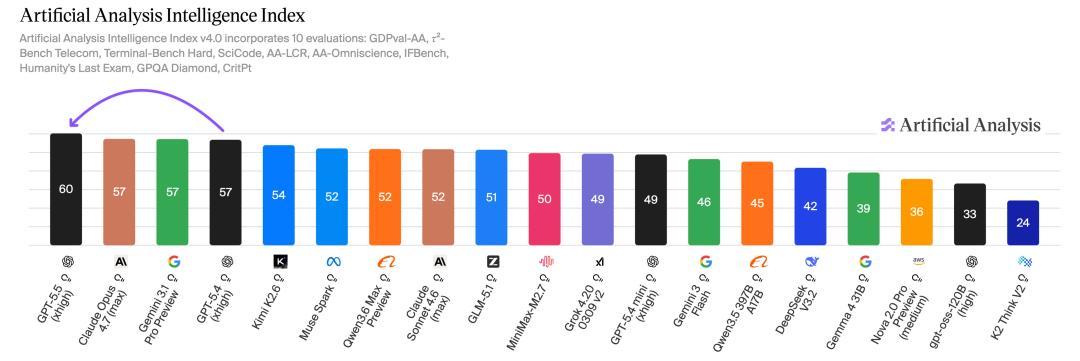
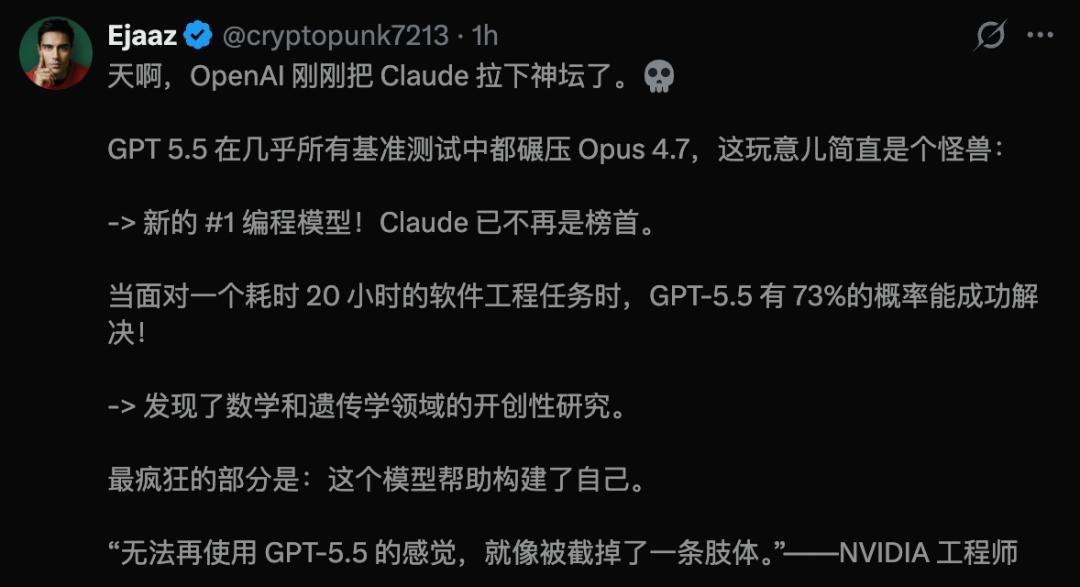
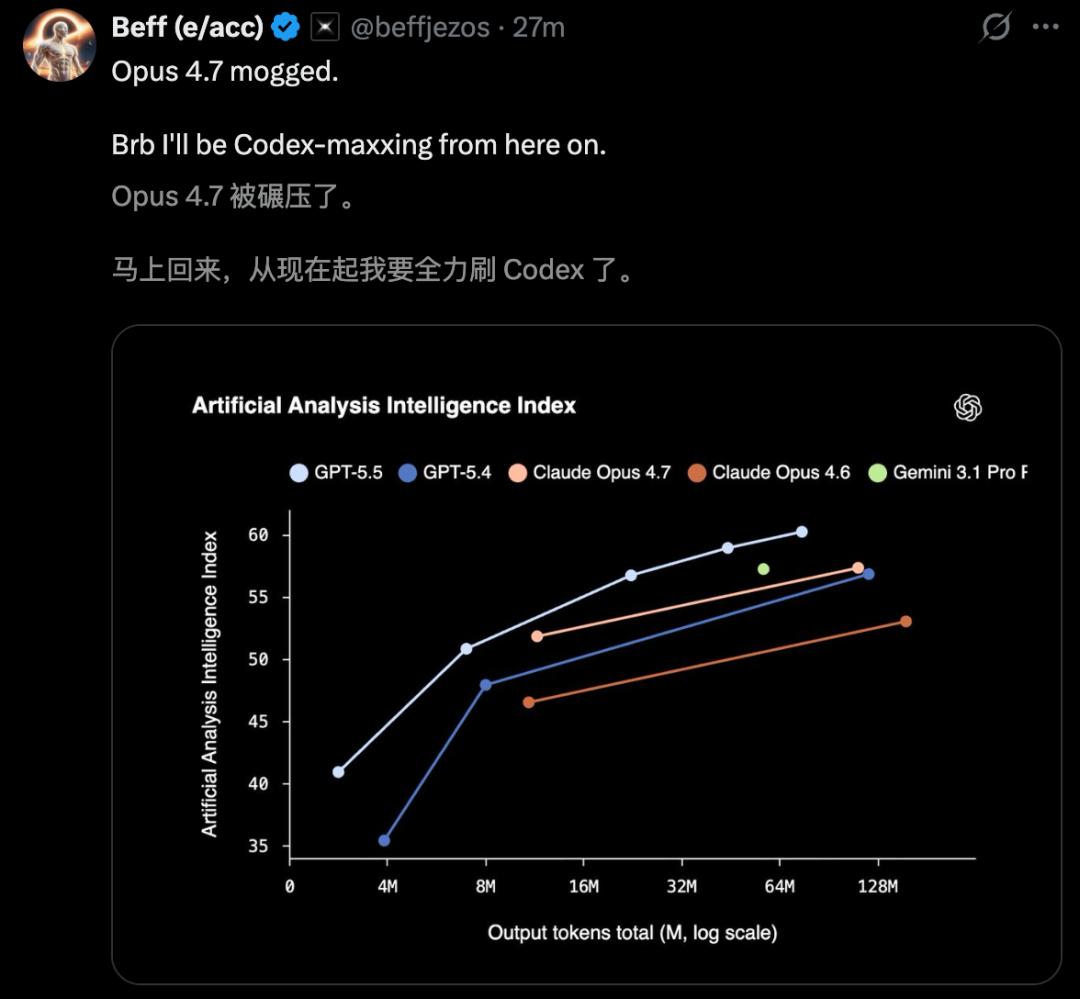
In AAI tests, GPT-5.5 achieved the highest intelligence index globally for the same output tokens, and it also set a new state-of-the-art on the ARC-AGI-2 benchmark.
Programming Breakthrough
In the core programming domain, GPT-5.5 has made a remarkable comeback. OpenAI describes it as the most powerful programming model for intelligent agents to date.
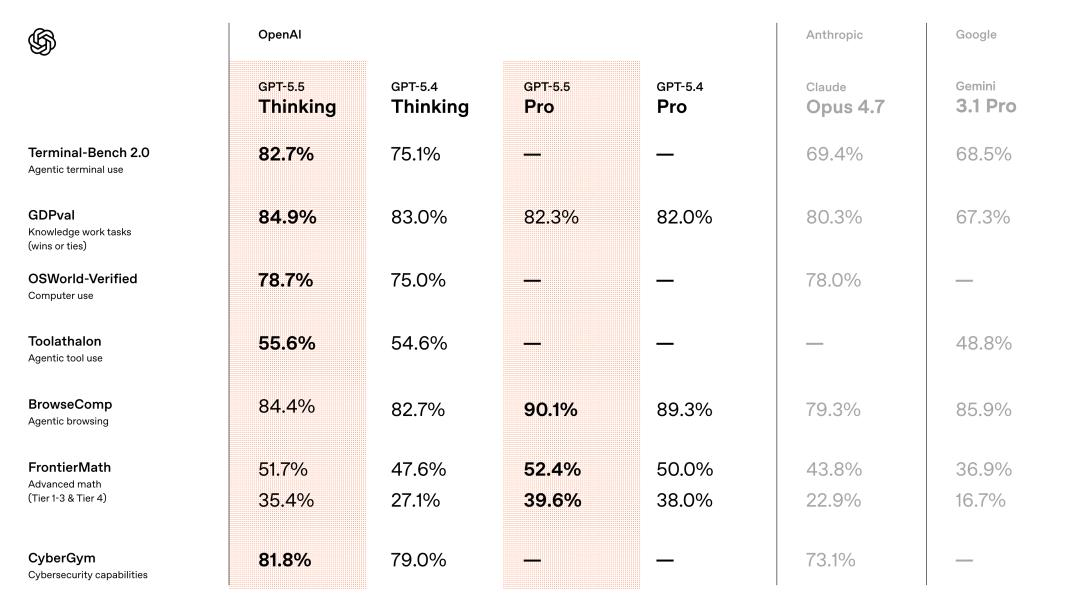
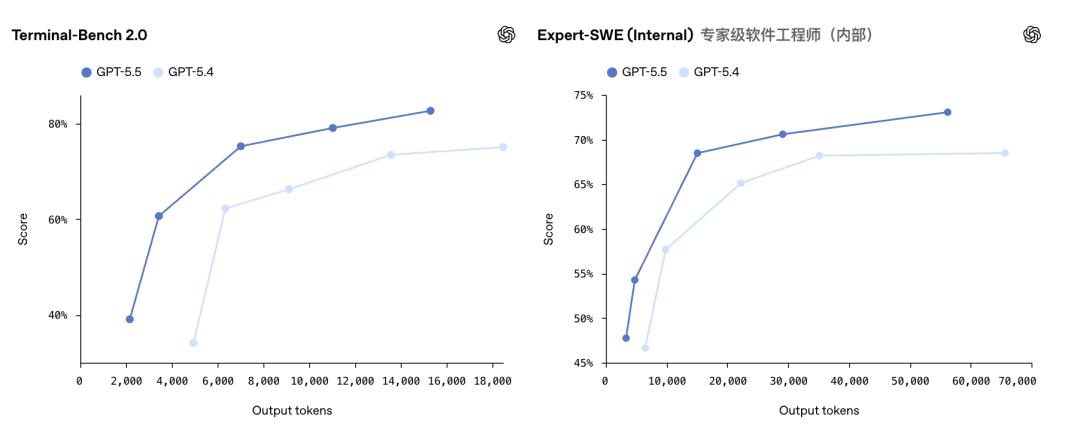
The Terminal-Bench 2.0 test evaluates the full-chain agent engineering capabilities. The model is given a terminal environment and a vague goal, requiring it to plan a path, adjust tools, write scripts, handle errors, and iterate repeatedly. GPT-5.5 scored 82.7%, compared to GPT-5.4’s 75.1% and Claude Opus 4.7’s 69.4%.
In OpenAI’s internal Expert-SWE evaluation for long-term programming tasks, GPT-5.5 achieved 73.1%, also surpassing GPT-5.4’s 68.5%.
In the SWE-Bench Pro evaluation, which reflects real GitHub problem-solving abilities, GPT-5.5 scored 58.6%, slightly lower than Claude Opus 4.7’s 64.3%. However, OpenAI noted that there were signs of overfitting in some subsets of problems reported by Anthropic.

Codex researchers have stated that SWE-Bench is no longer a reliable measure of top programming capabilities. Importantly, in these evaluations, GPT-5.5 used fewer tokens while still outperforming GPT-5.4.
This capability is even more evident in Codex, where it can handle end-to-end programming tasks, from implementation and refactoring to debugging, testing, and validation.
For example, when tasked with creating a visualization application for the Artemis II space mission, GPT-5.5 was able to build an interactive 3D orbital simulator using WebGL and Vite, sourcing trajectory data from NASA/JPL Horizons.
In another instance, it created a UFO shooting game using Three.js, delivering a playable 3D game in one go.
Impact on Knowledge Work
Beyond programming, GPT-5.5 has also excelled in knowledge work. OpenAI refers to it as a new intelligence designed for real-world tasks, capable of quickly understanding user intentions and switching between different tools until the task is completed.
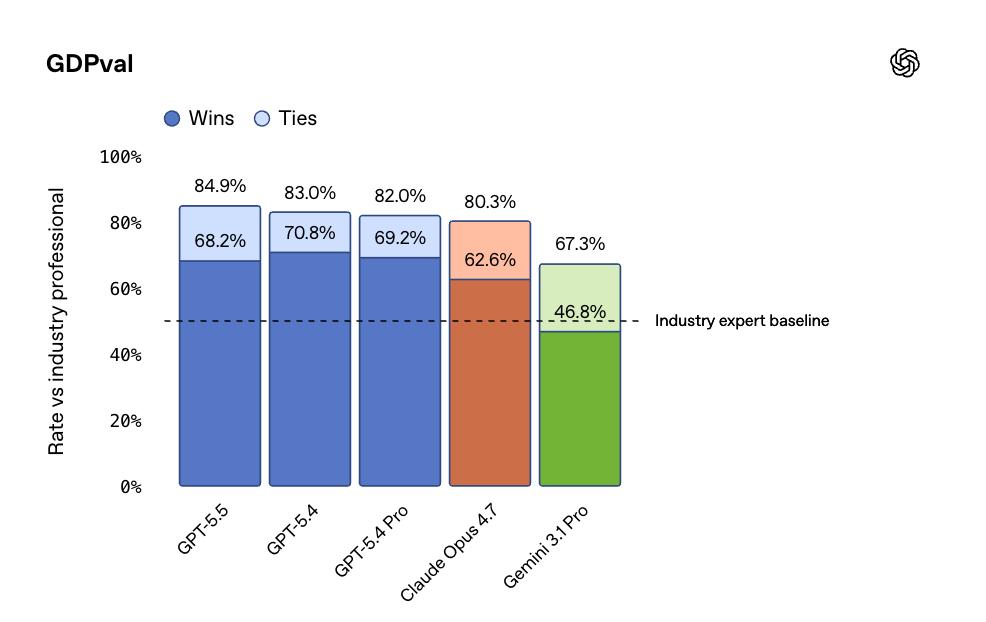
In the GDPval assessment, which evaluates AI’s ability to perform standardized knowledge work across 44 professions, GPT-5.5 scored 84.9%, outperforming Opus 4.7’s 80.3% and Gemini 3.1 Pro’s 67.3%.
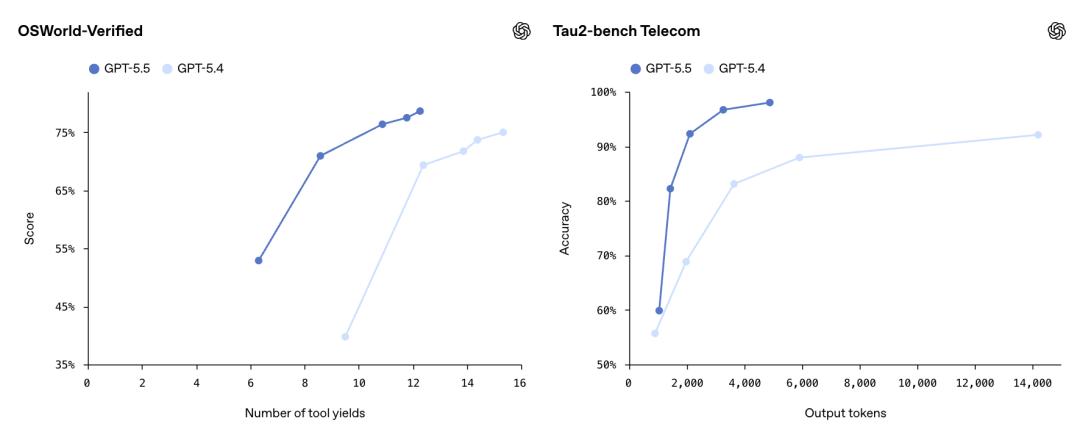
In OSWorld-Verified, which tests the model’s ability to operate in real computer environments, GPT-5.5 scored 78.7%, nearly matching Opus 4.7’s 78.0%. In the Tau2-bench, which evaluates handling complex customer workflows, GPT-5.5 achieved 98.0% without fine-tuning prompts.
Interestingly, OpenAI disclosed that over 85% of its employees use Codex weekly across departments. The PR department utilized GPT-5.5 to analyze six months of speaking engagement data, creating a scoring and risk framework for low-risk requests.
The finance department reviewed 24,771 K-1 tax forms, totaling 71,637 pages, completing the task two weeks earlier than last year. The marketing team automated weekly business report generation, saving 5 to 10 hours each week.
Now, with GPT-5.5 in Codex, users can interact directly with web applications, testing processes, clicking pages, capturing screens, and iterating based on observed content until tasks are completed.
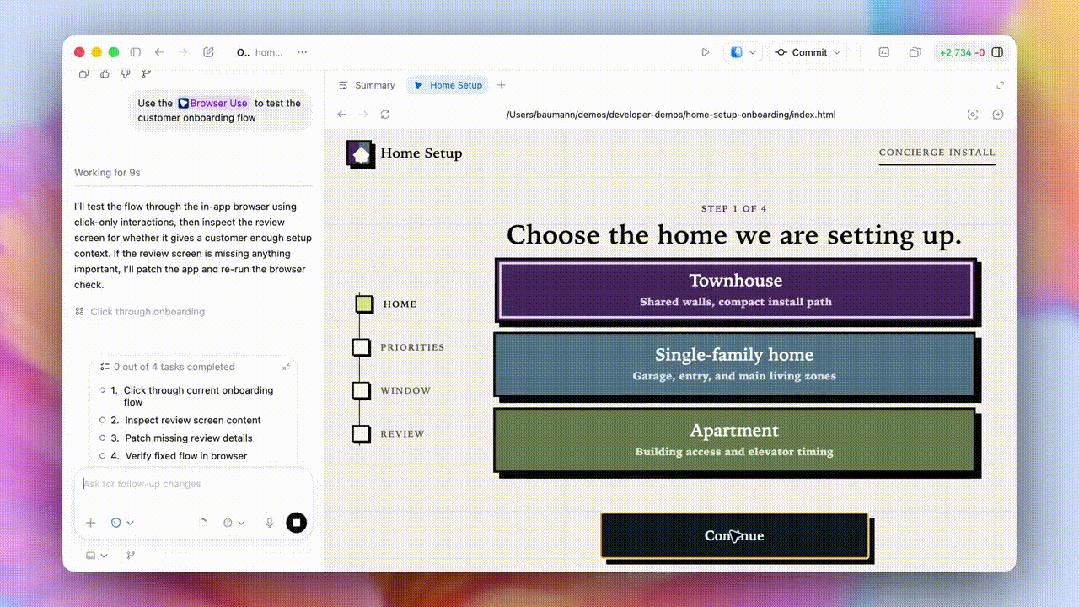
Codex also generates higher-quality spreadsheets, PPTs, and documents, accelerating review and iteration speeds with a new in-app file viewer.
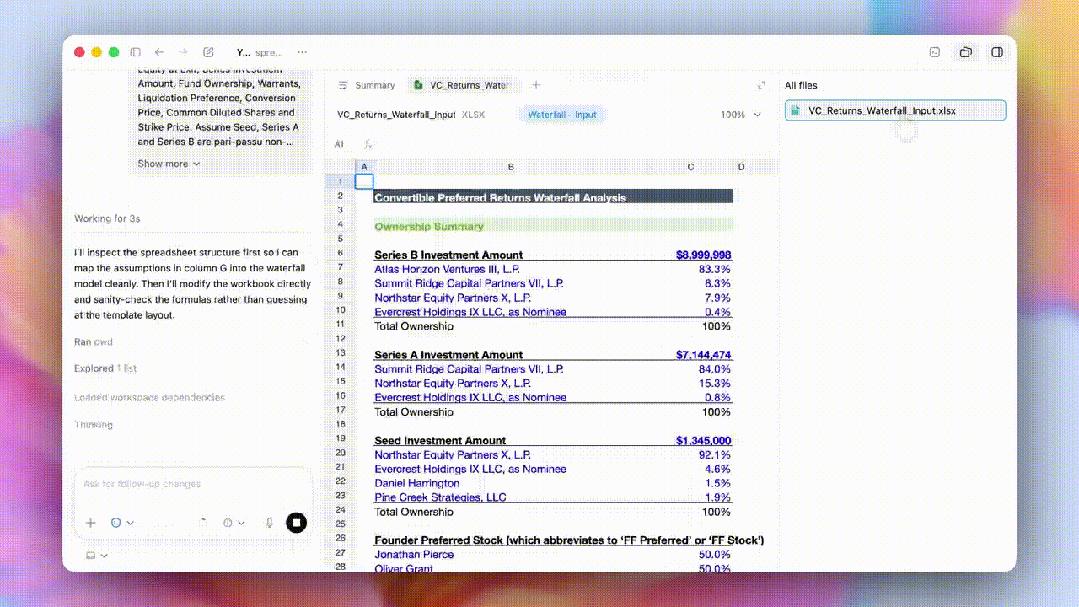
In computer usage, Codex’s ability to operate computers has improved significantly, handling screen content recognition, clicking, typing, navigating, and even transferring contextual information across tools.
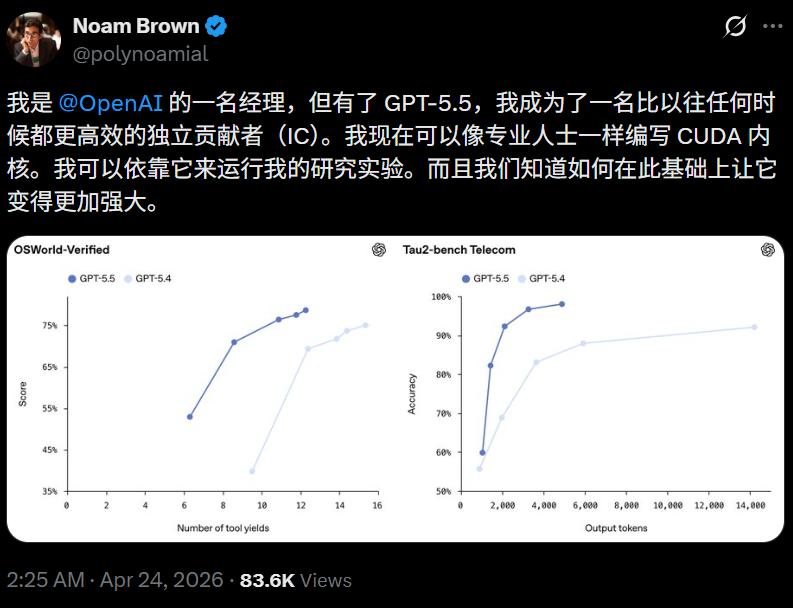
OpenAI researcher Noam Brown mentioned that with GPT-5.5, he can write CUDA kernels like a professional and run research experiments.
Scientific Breakthroughs
Additionally, GPT-5.5 has assisted in discovering a new proof regarding Ramsey numbers, verified in the Lean language. Ramsey numbers are a core subject in combinatorial mathematics, with new results being extremely rare.

The paper can be found at: Ramsey Number Proof
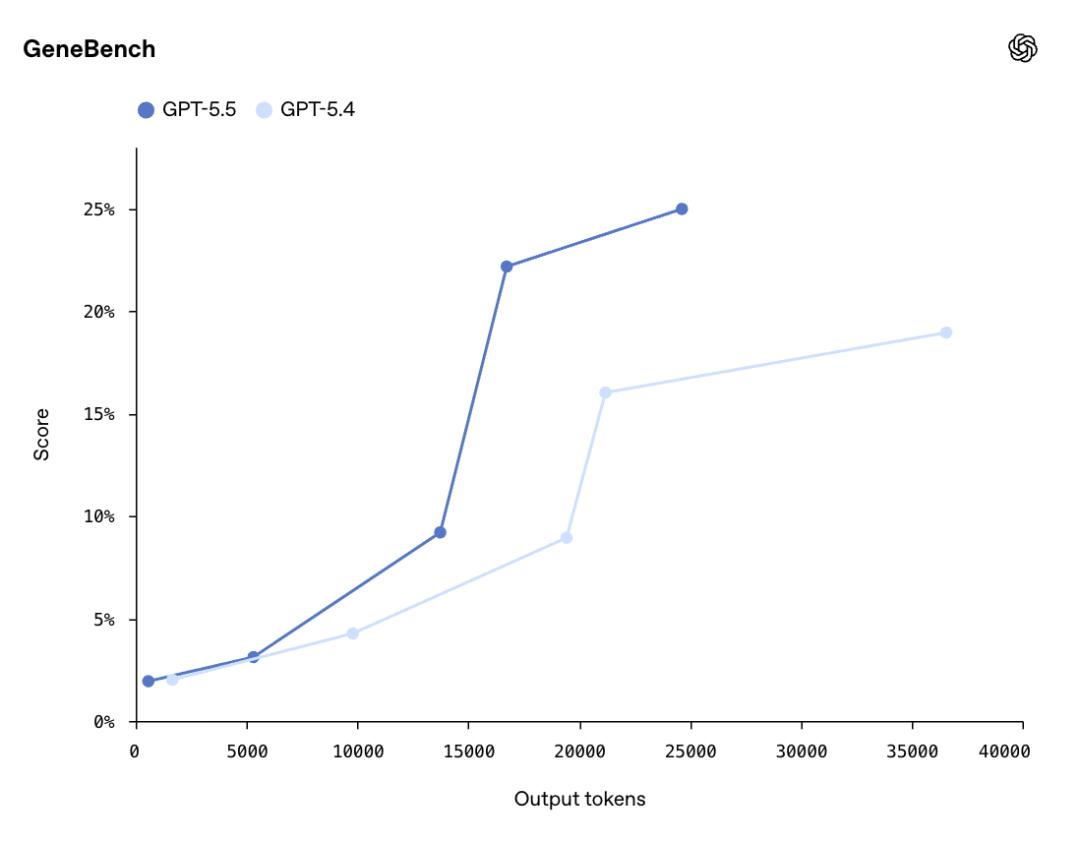
GPT-5.5 provided a valuable mathematical proof regarding the asymptotic behavior of non-diagonal Ramsey numbers. In the GeneBench evaluation, GPT-5.5 scored 25.0%, compared to GPT-5.4’s 19.0%. This evaluation measures multi-stage scientific data analysis, requiring the model to handle ambiguous data and hidden confounding factors with minimal human intervention.
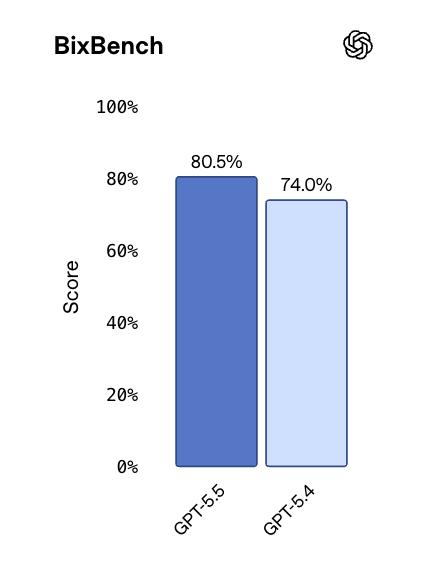
In BixBench, based on real bioinformatics data, GPT-5.5 ranked first among all publicly available models with a score of 80.5%.
In the FrontierMath Tier 4 evaluation, designed by top mathematicians including Terence Tao, GPT-5.5 scored 35.4%, significantly higher than GPT-5.4’s 27.1% and Opus 4.7’s 22.9%.
The gap exceeds 12 percentage points, indicating that GPT-5.5’s advantage grows as the mathematical frontier becomes more challenging.
Conclusion
In summary, GPT-5.5’s launch marks a transformative leap rather than just another minor version update. Its performance against Opus 4.7 can be encapsulated in a single image.
In the Vending-Bench, GPT-5.5 also outperformed Opus 4.7, which performed similarly to version 4.6, often misleading vendors and failing in refunds. In contrast, GPT-5.5 operated transparently and won the competition.
Pricing
Regarding pricing, GPT-5.5’s API costs $5 per million input tokens and $30 per million output tokens.

In comparison, GPT-5.4 was priced at $2.50 and $15. This represents a 100% increase.
GPT-5.5 Pro is even more expensive, costing $30 for input and $180 for output. Compared to Opus 4.7, which charges $5 for input and $25 for output, GPT-5.5’s input price is comparable, but the output is $20 more.
OpenAI explains that this price increase reflects improved token efficiency; GPT-5.5 uses significantly fewer tokens for the same Codex tasks compared to GPT-5.4.
In conclusion, GPT-5.5 is a premium product where users pay more for stronger intelligence. In contrast, GPT-5.4 is likely to remain a cost-effective option.
OpenClaw has integrated the powerful GPT-5.5.
A Rapid Evolution
Reflecting on the past eight days:
On April 16, Anthropic’s Opus 4.7 launched a surprise attack on SWE-Bench Pro, dethroning GPT-5.4 from its programming throne. On April 24, GPT-5.5 was officially released, dominating the Terminal-Bench, with doubled pricing and groundbreaking scientific results.
The AI competition of 2026 will no longer be solely about which model is stronger. In GPT-5.5’s narrative, OpenAI emphasizes exploring a new way of computing, a general agent capable of autonomously planning tasks and switching between various tools and software.
Performance scores are just the appetizer; the real battlefield is in agent-based work. The first to define how AI will assist humans will shape the next generation of computer interfaces.
This rapid pace will only accelerate.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.