Introduction
Recently, a Claude Code plugin called “Caveman” has gained significant attention on Hacker News.
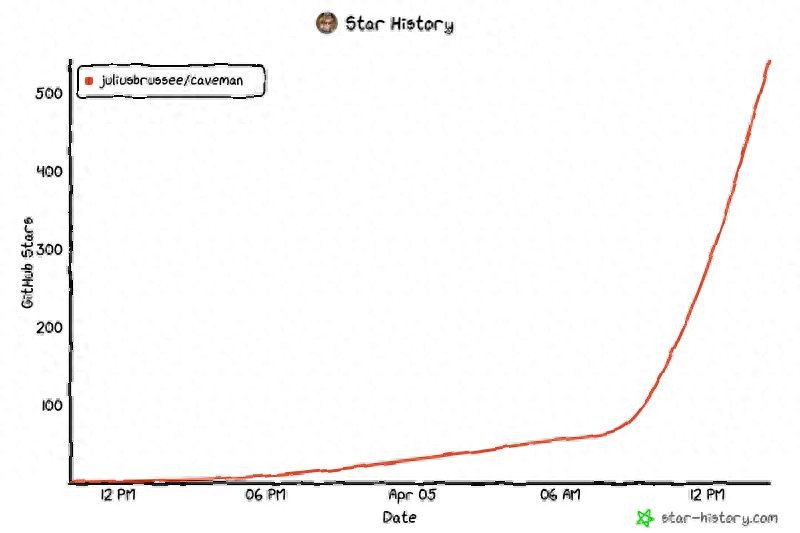 The GitHub star growth curve for “JuliusBrussee/caveman” shows a slow initial rise, followed by a sharp increase:
The GitHub star growth curve for “JuliusBrussee/caveman” shows a slow initial rise, followed by a sharp increase:
In just half a day, the star count surged from dozens to over 500, and it has now surpassed 20,000!
 The Caveman plugin has become famous for its token-saving capabilities!
The Caveman plugin has become famous for its token-saving capabilities!
The rapid rise of Caveman is a classic case of community resonance, addressing the pain point of “AI Yap”—a term for unnecessary verbosity that many users find frustrating.
Soon, users began calling Caveman the “best prompt technique of 2026,” claiming it can eliminate tokens wasted on polite phrases like “I’m happy to help.”
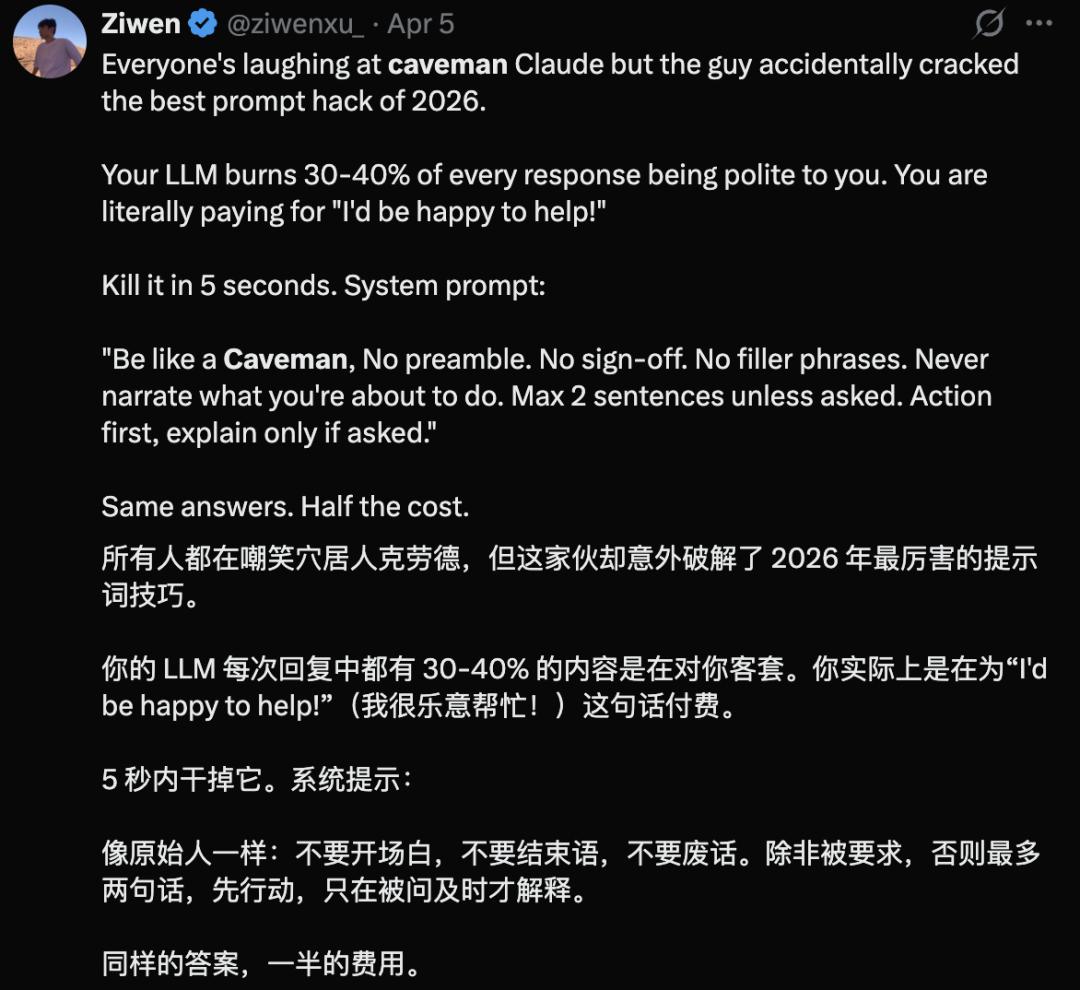 This plugin essentially simplifies AI communication to a caveman-like style.
This plugin essentially simplifies AI communication to a caveman-like style.
 It removes words like “the,” “please,” and “thank you,” along with any other polite language that consumes tokens without affecting technical meaning.
It removes words like “the,” “please,” and “thank you,” along with any other polite language that consumes tokens without affecting technical meaning.

Developed by Julius Brussee, the GitHub repository is named “JuliusBrussee/caveman.” In the README, Julius poses a straightforward question: why use so many tokens to say what can be expressed with fewer?
 This skill/plugin is compatible with both “Claude Code” and “Codex.” Its core idea is to make the AI agent speak like a caveman, compressing output without sacrificing technical accuracy, claiming to reduce token consumption by about 75%.
This skill/plugin is compatible with both “Claude Code” and “Codex.” Its core idea is to make the AI agent speak like a caveman, compressing output without sacrificing technical accuracy, claiming to reduce token consumption by about 75%.
 However, this raises the question: can removing articles and polite expressions really save users three-quarters of their costs?
However, this raises the question: can removing articles and polite expressions really save users three-quarters of their costs?
How Does Caveman Save Tokens?
How does Caveman actually achieve its token savings?
Opening its core file, SKILL.md, reveals that the content is quite brief.
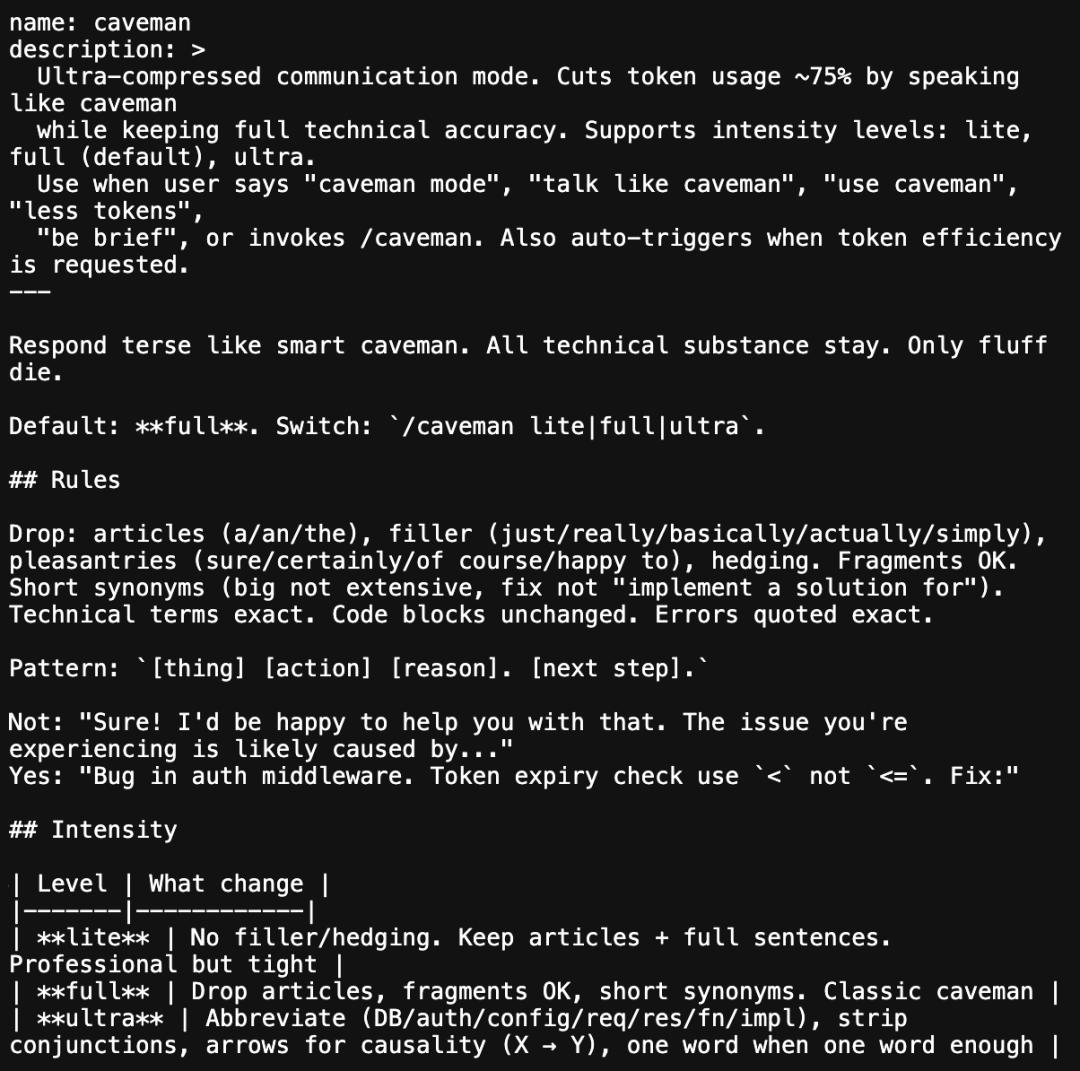
The file defines it as an “Ultra-compressed communication mode.”
It states:
By speaking like a caveman, the goal is to lower token usage while maintaining technical accuracy.
Users can activate this mode by saying “caveman mode,” “talk like caveman,” “use caveman,” “less tokens,” or by invoking “/caveman.” It can also be triggered automatically when users explicitly request higher token efficiency.
The rules for saving tokens are straightforward: avoid articles, eliminate filler words, and skip polite expressions; retain technical terms and code blocks, and cut anything else that can be removed.
The following content should be deleted: articles, filler words, polite phrases, and hedging expressions.
Short and fragmentary sentences are permitted.
Prefer shorter synonyms, such as using “big” instead of “huge,” or “fix” instead of “implement a solution.”
Technical terms must remain precise, and code blocks should not be altered. Error messages must be quoted verbatim.
Recommended sentence structure: [Problem][Action][Reason].[Next Step].
For example, instead of writing: “Of course! I’m happy to help. The issue you’re encountering is likely caused by…” it should be: “Bug in auth middleware. Token expired check used.”
It supports three levels of intensity: lite, full (default), and ultra.
- lite: Removes filler words and hedging expressions while retaining complete sentences and normal written tone. Professional and concise;
- full: Further compresses expressions, allowing omission of some function words, fragmentary sentences, and shorter word substitutions. Typical caveman style;
- ultra: Uses many abbreviations, such as DB, auth, config, req, res, fn, impl; eliminates conjunctions; expresses causality with arrows, like “X→Y”; uses one word when possible instead of two.
For example:
- lite: “The connection pool reuses already opened database connections instead of creating new ones for each request, avoiding repeated handshake overhead.”
- full: “Connection pool reuses opened DB connections. Not every request creates new ones. Saves handshake overhead.”
- ultra: “Connection pool=reuse DB connections. Skip handshake→faster high concurrency.”
Of course, when encountering security warnings, irreversible operation confirmations, multi-step processes, or when users are clearly confused, clear expression remains a priority. This exception logic is also explicitly stated in SKILL.md.
There are no changes to the model architecture or reasoning mechanisms; Caveman is essentially a carefully crafted system prompt that constrains the AI’s output style.
A crucial point: the author, Julius Brussee, clarified in the HN discussion thread that this skill does not target hidden reasoning tokens and thinking tokens.
 The model’s internal reasoning process does not automatically shorten with Caveman; it primarily compresses the visible output.
The model’s internal reasoning process does not automatically shorten with Caveman; it primarily compresses the visible output.
Anthropic’s official documentation also mentions that the names and descriptions of skills themselves consume context budget.
In other words, loading the Caveman skill itself consumes tokens.
Thus, the true end-to-end cost savings may not equal the eye-catching “75%” stated in the README.
Therefore, while Caveman likely significantly compresses the visible output length, this should not be directly interpreted as a proportionate decrease in total costs.
Is the 75% in the README Reliable?
From the public content of the repository, the author indeed provides benchmark scripts and lists several tasks’ token comparisons in the README, ranging from 22% to 87%, with an average of 65%.
However, as of now, what can be directly seen in the public repository are the testing scripts and example tables; it remains difficult for outsiders to fully verify each result’s reproducibility based solely on the current repository content.
 The author stated in the HN post that this is just preliminary testing, not a rigorous benchmark test.
The author stated in the HN post that this is just preliminary testing, not a rigorous benchmark test.
However, the question of whether concise expression harms AI performance has indeed been studied in academia.

A 2024 paper titled “The Benefits of a Concise Chain of Thought on Problem-Solving in Large Language Models” shows:
When researchers asked models to use a more concise reasoning chain, the average response length of GPT-3.5 and GPT-4 decreased by 48.70%, while overall problem-solving ability showed no significant decline; however, for math problems, GPT-3.5’s performance dropped by an average of 27.69%.
A 2026 paper titled “Brevity Constraints Reverse Performance Hierarchies in Language Models” further points out:
In some benchmarks, adding brevity constraints to large models can improve accuracy by 26 percentage points, potentially changing the performance rankings among models of different sizes.

These two papers provide a research background for the idea that brevity does not necessarily harm performance.
However, it must be clarified that they study the effects of brevity as a general prompt strategy, not a specific evaluation of the Caveman GitHub repository.
The README’s references to these studies can at most indicate that its approach is not without theoretical background, but cannot be taken as a strict validation of the project’s effectiveness.
The Emergence of the Claude Code Plugin Ecosystem
Another background reason for Caveman’s popularity is:
Anthropic has provided a relatively complete skill and plugin mechanism for Claude Code.
 According to Anthropic’s official documentation, developers only need to create a SKILL.md file for Claude to recognize it as a skill; the description determines when it is automatically loaded, while the name becomes a directly triggerable slash command.
According to Anthropic’s official documentation, developers only need to create a SKILL.md file for Claude to recognize it as a skill; the description determines when it is automatically loaded, while the name becomes a directly triggerable slash command.
 The official documentation also clearly states that the path structure for plugin-level skills is:
The official documentation also clearly states that the path structure for plugin-level skills is:
In the Caveman repository, there are indeed directories like .claude-plugin, plugins/caveman, and skills/caveman, indicating that it is not just a toy limited to a few prompts, but an extension packaged according to Claude Code’s skill/plugin mechanism.
 This means developers can indeed change how Claude Code operates and its output style for specific tasks through a SKILL.md without altering the underlying model.
This means developers can indeed change how Claude Code operates and its output style for specific tasks through a SKILL.md without altering the underlying model.
In a sense, this resembles the early VS Code extension ecosystem:
A batch of seemingly lightweight extensions with a touch of humor emerged first, and then gradually evolved into more serious and specialized workflow tools.
Developers Have Long Suffered from AI Verbosity
Returning to the initial question: is Caveman actually useful?
If viewed strictly as a “cost-saving tool,” caution is needed.
It only compresses visible output text and does not touch hidden reasoning tokens, which often constitute the bulk of Claude Code’s costs.
Additionally, the skill itself consumes context, so the real end-to-end savings are unlikely to reach 75%.
To truly optimize token costs, the key lies elsewhere. Model layer calls, context window management, prompt engineering, and caching strategies are the real battlegrounds.
However, what makes Caveman noteworthy is not whether it has provided a perfect solution, but that it serves as a signal.
When a developer creates a plugin to “make AI say less nonsense” and shares it on GitHub, sparking serious discussions among thousands of users and going viral on HN, the focus has shifted.
It indicates that the verbosity of AI tools is no longer just a tolerable minor issue but has become serious enough for users to take corrective action themselves.
In fact, developers have long been emotionally overwhelmed: a glance at major communities reveals countless complaints about AI verbosity:
I only need two lines of regex code, yet it insists on writing five paragraphs of regex history; Please stop saying “Certainly! Here is the…” and just give me the error or the code.
On Hacker News, these laments are often linked to usage costs:
I’m spending $15 for 1 million tokens just to read AI’s apologies and pleasantries.
Just to change a punctuation mark, it rewrote the entire 800-line file, and I can visibly see my API balance dropping. I’m about to go bankrupt.
…
When users prefer that AI communicate like a caveman rather than continue paying for redundant output, it may be time for mainstream AI companies to reflect.
Why, to this day, have they not made “restraint” a fundamental capability?
Instead of solely focusing on computational power, they should seriously consider why users are increasingly intolerant of unnecessary output.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.